
文 | 硅谷101,作者|陈茜
音乐,对你来说,是什么?
音乐对于我们中的许多人来说,是生活中不可或缺的一部分。它不仅仅是娱乐,更是一种情感的表达和交流方式。音乐是一种语言,可以用来表达感受,描绘作曲家想要传达的某种情绪或感觉,同时每个人也会对原始乐谱进行自己的解读。
但在2024年,我听到了一个截然不同[百家号vnmp.cn]的答案。

如果以“微小单元空气震动的排列组合”来定义音乐,这简直太符合这一轮生成式人工智能的能力覆盖范围了。
果不其然,在2024年,以Suno为首的众多AI音乐模型和产品爆火,这些用简单提示词、几十秒就能生成的AI作词、作曲、演唱曲目,效果好到让人大为震撼。
音乐AI模型是怎么发展起来的?中间的技术细节[百家号vnmp.cn]是如何实现的?AI音乐目前能否替代人类歌手或音乐家呢?以及AI浪潮将会如何影响整个音乐产业市场?
硅谷101接触了AI音乐模型从业者、打击乐教授、乐队和各种乐器的演奏者,和大家一起来共同探索AI音乐的颠覆与技术边界。
01 Suno AI的风靡与争议2024年5月末,总部位于波士顿的AI音乐公司Suno在[百家号vnmp.cn]社交媒体X上宣布成功完成了1.25亿美元的 B轮融资,投后估值达到5亿美元,用户数量快速增长至超过1000万。微软等科技巨头更是将 Suno的AI音乐创作功能直接整合到了旗下的Copilot产品中。

像这轮AI浪潮中的众多明星项目一样,Suno的创立时间很短,2022年才成立,在B轮融资之前公司仅有1[百家号vnmp.cn]2人。
在2024年3月,Suno突然爆火。Text to music,文生音乐的能力巨大提升,让大家惊呼:AI音乐的ChatGPT时刻,就这么到来了。
乍一听,真的觉得AI作曲已经非常好听了,不管是曲调,还是歌词,还是歌手唱腔,作为一个音乐小白和唱歌经常走调的人,我觉得这些歌已经非常好听,远超现在的一[百家号vnmp.cn]些十八线歌手的网络口水歌。而这会不会掀起音乐市场和唱片公司这些资本方的腥风血雨呢?
2024年6月底,根据美国唱片业协会(Recording Industry Association of America, RIAA)的官方通告,包括索尼、环球和华纳在内的三大唱片公司及旗下厂牌集体向Suno和另外一家[百家号vnmp.cn]AI音乐应用Udio发起诉讼。起诉状中提供了旋律雷同的例子和细节对比分析,而原告要求每一首侵权作品需赔偿15万美元。

这个官司打出结果可能还需要一段时间,不过我其实对这起诉讼也并不感到意外。首先,AI音乐的出现势必会动到传统音乐资本的市场蛋糕,肯定会引发抵触,这个市场蛋糕是具体哪一块我们稍后会分析。
其[百家号vnmp.cn]次,在Suno刚火起来的时候,有AI模型的业内人士就对我们表达过怀疑,他们认为,Suno的效果这么好,可能是因为用了有版权的音乐做训练。
我们在这里不作任何的结论,只是单纯的传达出业内人士的困惑:他们认为,AI音乐这个产品很多科技公司,如果说谷歌和Meta都在做,但效果都不如Suno AI,难点都不在[百家号vnmp.cn]模型本身,难点是在于可以用来训练的参数,也就是没有版权问题的歌曲。
比如说:一线歌手的流行音乐不能用,有版权;影视作品音乐不能用,有版权;就连已经算作public domain(公有领域)的交响乐,只有曲谱是没有版权问题的,而被各大乐团演奏出来的版本依然是有版权限制的,也是不能拿去做AI训练的。
也就是[百家号vnmp.cn]说,可能人类目前最顶尖的音乐作品,很大一部分都是无法摆脱版权问题而拿去给AI训练的。那么谷歌和Meta怎么解决这个问题呢?
作为科技巨头,他们花了天价,去雇一群音乐创作人,专门给他们自己创作不同类型的音乐,然后用这些没有版权顾虑的音乐去训练自己的AI音乐模型。这个成本,显然是Suno等小创业公司无法去[百家号vnmp.cn]负担的。
这场官司会如何发展,Suno到底有没有用有版权的音乐训练模型,我们也会继续关注事态的发展。
不过,我们来继续聊点好玩的,这期节目我们也邀请到了Meta的Music Tech Lead(AI音乐技术主管)Roger Chen,来跟我们一起详细聊一下AI音乐模型的细节。
02 AI音乐模型拆解Chap[百家号vnmp.cn]ter 2.1 第一层压缩及码本
Roger就告诉我们,用机器学习做音乐这件事情已经做了好几年了。在业界大家已经意识到,如果“音乐的定义”可以被理解成,声音在空气中的震动产生不同的频率和幅度,那我们可以把声音标记成电信号。

我们知道,在如今基于Transformer架构的大语言模型中,token代表模型[百家号vnmp.cn]可以理解和生成的最小意义单位,是模型的基础单位。
而在AI音乐中,各种音乐维度都可以表达成token序列,包括:节奏、速度、和声、调性、段落、旋律、歌词还有唱腔音色等等,一切皆可token化。
但是,这里的技术难题是:音频中的信息太丰富了。举个例子:音乐被录制下来之后,如果用离散的数字来表示,每秒钟通常[百家号vnmp.cn]是有44100个采样。如果大家仔细看之前买的CD,上面会标注44.1kHz的字样。
如果1秒有44100个采样,那么3分钟的一首歌,就有3×60×44100=7938000这么多个采样。如果把每个采样都对应一个token,那么对于模型训练来说是一个天文数字。

如何将音频token化,这成为了AI在音乐模[百家号vnmp.cn]型上发展的难题。直到几年前,Meta和谷歌在音频采样压缩技术上出现了技术突破,能实现将音频采样转化为更少量的token,其中的压缩幅度达到几十几百倍,因此,AI音乐的发展才开始提速。


Google的SoundStream,以及Meta的EnCodec技术,能让3分钟音乐的7938000采样,被大幅度压[百家号vnmp.cn]缩到以几毫秒甚至几十毫秒的长度来计算的token序 列。每一个token,都可以用一个数字对应表示。


用数字表现音频,这被称为codebook(码本)。在实际操作中,人们发现,当把音乐转换成一串数字的时候,它会有一定的程度的失真。也就是说,码本的大小会决定音频的质量。
Roger Chen
Meta音乐技[百家号vnmp.cn]术负责人
假如说我们一共只用1000个数字来表示天底下所有的音频的话,那么它失真会非常严重,但是我们用100万个,那可能失真就不那么严重了。
然而,虽然从事AI音乐的研究员们意识到大语言模型理解和生成token的方式是一种新的生成音乐的方式,但难点是,音乐的序列很长。比如每个token代表5毫秒,3分钟[百家号vnmp.cn]的歌曲就有36000个token。
即使谷歌和Meta的压缩技术已经将三分钟音频的7938000个采样的信息量压缩到了36000个token,已经缩小了这么多倍,但依然,这样的token量对于大语言模型来说,还是太大了。
这就形成了一个悖论:码本小,失真严重,效果不好;码本大,效果好,但token量太大[百家号vnmp.cn]而没法拿去GPT生成。
由于这么大的token量无法用GPT模型来完成,在AI音乐的前几年,效果一直没那么惊艳。
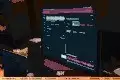
当时,AI生成音乐的普遍做法是把音频先转换成频谱frequency spectrum,就是这种图,然后再用图片的方式从扩散模型diffusion model去生成。扩散模型的AI生成原理我们[百家号vnmp.cn]在之前讲Sora视频生成的时候详细讲过,感兴趣的小伙伴可以去往回翻去看看那期。

但是,用扩散模型生成出来的音频效果非常不好,因为模态转换期间,会有很多细节信息丢失,导致生成成品的失真。而如果要用GPT模型的话,必须要解决音乐序列长、token太多的问题。这个时候,又一个重要的技术出现了突破:第二层音频[百家号vnmp.cn]压缩技术。Chapter 2.2 第二层音频压缩技术简单来说,在基本无损音频信息的情况下,人们发现,音频token还能被继续压缩。首先,研究员们发现,音频的token可以进行分层压缩及解码,来减小大模型中Transformer架构的上下文压力。我们刚才说3分钟的音乐有36000个token,如果将这[百家号vnmp.cn]些token序列三个分为一组,先将它们打包,在这一层做一个小小的压缩,36000个token就被压缩到12000个token了,然后放进Global Transformer大语言模型,等模型输出了12000个token之后,再把每个token通过Local Transformer展开成三个原来的to[百家号vnmp.cn]ken数量。

所以,这样将Token先压缩分层,再展开的方式让大模型的上下文压力减小,也能让生成的时间变得更快。从最开始的三分钟音乐的7938000个采样,到如今的12000个token,这么多倍的压缩。才有了AI音乐大模型的风靡全球。而我们不排除以后有技术可以把音频token量压缩得更小,让音乐生成[百家号vnmp.cn]更快、更顺滑、有更多的细节和信息。我们来总结一下:先是将音乐token化的技术,加上近年音频压缩技术的出现和发展,伴随着GPT这样的大语言模型能力的增强,还有text to speech(文生语音)模型的进步,使得AI音乐的能力得到了飞速提升,无论在作曲、作词还是演唱上,都越来越逼真、越来越拟人。这[百家号vnmp.cn]也就造就了Suno AI的爆火。从Roger跟我们的分析来看,只要AI学了足够多的参数和曲目,就可以生成任何风格的作品。

所以,如果你是一个音乐从业者的话,面对如今AI音乐的能力,你是否担心自己的工作不保呢?AI音乐会对我们的娱乐产业造成颠覆性的影响吗?音乐家和歌手们的饭碗还能保得住吗?我们跟一众音乐[百家号vnmp.cn]家们聊了聊,但好像,大家并没有太担心被取代这件事情。那么,AI取代的会是谁呢?
03 AI音乐带来的颠覆Chapter 3.1 AI能替代人类音乐家吗?
在做Suno和AI音乐这个选题的前后这么几个月的时间,我自己也在尝试不同的作曲,试试各种的prompt词和调里面的变量,还是挺好玩的,我也会去听听Sun[百家号vnmp.cn]o或者其它AI音乐平台的榜单,听一下别人用AI创作的歌,真的很不错。我也建议大家都去玩玩看。

但是听久了我发现一个问题:AI创作出来的歌曲虽然乍一听还不错,但不会有那种让我一遍又一遍很上头的音乐,不会让我特别有感情上的共鸣,风格也慢慢变得很雷同。可能是训练参数的匮乏,让AI音乐很难创造出人类顶级水平的[百家号vnmp.cn]歌曲,因此我很难想象,这些AI音乐会在五年或者十年之后,有任何一首能经得起时间的检验,还能在人们之中口口相传。
那么,Suno在专业音乐人眼中是如何的存在呢?能掀起什么风浪呢?我们接触了知名音乐博主“叨叨冯”,也是我自己很喜欢看的一个频道。叨叨原名是冯建鹏,是美国Hartford大学音乐学院打击乐讲师[百家号vnmp.cn],也是纽约百老汇全职演奏家。他认为,AI目前可以达到音乐届的平均水平,但这样的平均水平,不足以在这个行业中出挑。

冯建鹏在自己的频道上也做了多期用AI作曲的视频,尝试了各种曲风,包括更细节严谨的prompt来控制乐器、节奏、音乐风格等等,结论是AI作曲还有非常多的缺陷,包括Suno无法理解钢琴的赋格,[百家号vnmp.cn]特定乐器的要求也没有达到,生成复杂一点的音乐形式,比如说交响曲,效果非常差。他认为,之后AI模型的能力肯定会越来越强,但距离替代音乐人还早,但如今音乐从业者也不用抗拒AI,反倒是可以利用AI来作为更好的创作工具。

而冯建鹏屡次提到的音乐“态度”和“情绪”,也是我们在跟众多音乐演奏者们聊天的时候他们提到[百家号vnmp.cn]的最多的关键词。他们认为,这是人类在演奏乐器或演唱的时候,最重要的元素。就如同,同样的一个曲谱,不同演奏者会有不同的解读和表现方式,而就算是同一首曲子同一个演奏者,他的每一次表演都是不同的,都是独一无二的。而情感的共鸣,是对于接受音乐欣赏音乐的作为观众的我们来说,最珍贵的部分。

建议大家可以去视频里听[百家号vnmp.cn]听Kevin演奏的不同风格的曲子。Chapter 3.2 版权音乐和口水歌将受冲击
我想了想,我会买高价票去看朗朗或者王羽佳的演奏会,但我估计不会买票去听机器人弹钢琴。那么问题来了,AI音乐,如果以现在的能力来看,它冲击的是什么市场呢?Meta Music and copyrights团队的技术负责人[百家号vnmp.cn]Huang Hao告诉我们,版权库音乐和口水歌市场将会是受到冲击的市场蛋糕。
第二阶段我觉得做口水歌的这些网红歌手可能就没了。其实在国内抖音上面几乎被这种非常低质量的口水歌完全占据了,这些歌你拿来做视频是非常有意思,因为它的节奏一般都很欢快,然后它的旋律实际上是大众都已经熟知的那些和旋。我觉得这些网红[百家号vnmp.cn]歌、口水歌可能会很快的被替代掉。
那什么是没法或者说很难去替代呢?就是很强的音乐人,比如说周杰伦,Taylor Swift、Billie Eilish这种,Coplay这些我觉得都很难(被替代)。所以非常有创意的这些音乐,我觉得还是有它存在的价值,但是可以看得到其实对音乐人,对整个市场,我觉得还是有很[百家号vnmp.cn]大的挤压的。
对于音乐创作者和演奏者来说,音乐的功能性和商品性也许慢慢会被AI替代,但音乐的精神共鸣层面永远处于个人。


那我们现在清楚了在音乐创作上和市场冲击上,AI音乐技术的边界。而在立法上,大公司们以及政策制定者们也正在行动,而这将更加规范AI音乐的未来发展。
04 诉讼、立法、零样本训练与AI音乐的未[百家号vnmp.cn]来在2024年7月12日,美国参议院的三位国会议员提出了一个针对AI版权的新法案COPIED Act,全称是The Content Origin Protection and Integrity from Edited and Deepfaked Media Act,直译过来是“内容来源保护和完整性[百家号vnmp.cn]防止编辑和深度伪造媒体法案”。

这个法案的目的,主要是制定完善的规则来标记、验证和检测生成式AI产品,包括文字、图片、音频和视频,提升生成内容的透明度防止被非法乱用以及保护公众的个人数据和隐私。同时保护记者、音乐人、演员和其他艺术、商业群体的利益,并保留对非法使用数据训练AI大模型的法律追究权益。
比如[百家号vnmp.cn]说,法案规定,任何商业生成式AI产品必须让用户知道这是AI生成的,比如说ChatGPT生成的广告文案或社交媒体帖子,一旦是商用范畴,就必须要明确标注是由AI生成,并且禁止任何人故意移除或篡改AI生成的标注信息。
另外这个法案重要的一点是给出了明确的赔偿机制,明确禁止AI厂商在未经明确、知情同意的情况下[百家号vnmp.cn],使用具有受版权保护作品的数字内容来训练AI大模型和算法。如果侵犯便需要进行赔偿。
这个法案一出,是受到了各种工会、唱片协会、新闻联盟等等组织的大声叫好。

所以,我们在开头提到的Suno被三大唱片公司起诉的官司可能会根据这个最新的法案来宣判指导,我们也会为大家继续关注这方面的法律进展。
但毫无疑问的是,技[百家号vnmp.cn]术和法律的关系,有时候,总是很模糊,经常是上有政策下有对策。
比如说,我最近学习到,AI音频上还有一个技术被称为“零样本训练”(Zero-shot learning)。
在学术上的解释是:训练AI模型来识别和分类对象或概念,而无需事先见过这些类别或概念的任何示例。

简单一点来说,就是把“数据”和“大模型的[百家号vnmp.cn]学习方式”给解耦合,比如说你告诉大模型我要生成一个跟某位歌手很像的声音,或者是一段这个乐器音色很像的曲子,那么通过“零样本训练”,大模型虽然没有见过或者通过特定样本训练,但它也可以模仿进行输出。
“零样本训练”目前在音乐生成上还没有被广泛应用,但在语音合成上已经很成熟了,所以我们可以预见,以后如果用户[百家号vnmp.cn]拿着几秒种的音频文件作为例子,大模型就可以迅速复制例子音色,这样的技术对产权保护更难监管。
突然想到,前段时间OpenAI在发布产品GPT-4o的时候,语音的音色被认为很像电影《Her》的配音演员斯嘉丽·约翰逊。而约翰逊爆料说,之前OpenAI CEO Sam Altman确实找过她希望用她的声音给4[百家号vnmp.cn]o配音,但她拒绝了。

但4o出来的语音模式,有一说一,确实很像寡姐在Her中的声音。
在GPT4o发布之后,约翰逊大为震惊和恼怒,虽然没有正式去OpenAI提起诉讼,但已经组织好了律师团队来准备下一步的法律动作。OpenAI这边是否认了使用约翰逊的声音作为训练样本,而是使用的另外一位配音演员。
我也不知道[百家号vnmp.cn]OpenAI是否使用了零样本训练的技术,但我相信,随着各种生成式AI技术和产品能力的提升,法律、商业以及社会都需要一些新的共识。
05 新的共识与不完美的人类但我想,不变的,依然是人类对音乐的需要,无论是听众还是演奏者,无论是大师还是我这样主要为了自嗨的业余小白。
人类的创作是充满不确定性的,有激进,有感[百家号vnmp.cn]性,有随心所欲,有喷薄而出的情感,有为了追求完美的一万小时定律,也有为了追求与众不同的铤而走险。
人类是会犯错的,但正是因为有这些错误,才让完美更加难能可贵。而当完美唾手可得,那艺术也不再是众人的信仰了。
AI的能力会持续进步,但人类的音乐追求也会持续进步。顶级的创造力,将不会被替代。
最后,我用Suno[百家号vnmp.cn]写了一首歌,prompt词大概是我们硅谷101从事科技与商业内容制作的愿景。很短的prompt,用几十秒就生成出来了,欢迎大家鉴赏、留言告诉我们,你们对AI生成音乐的看法。



发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。